
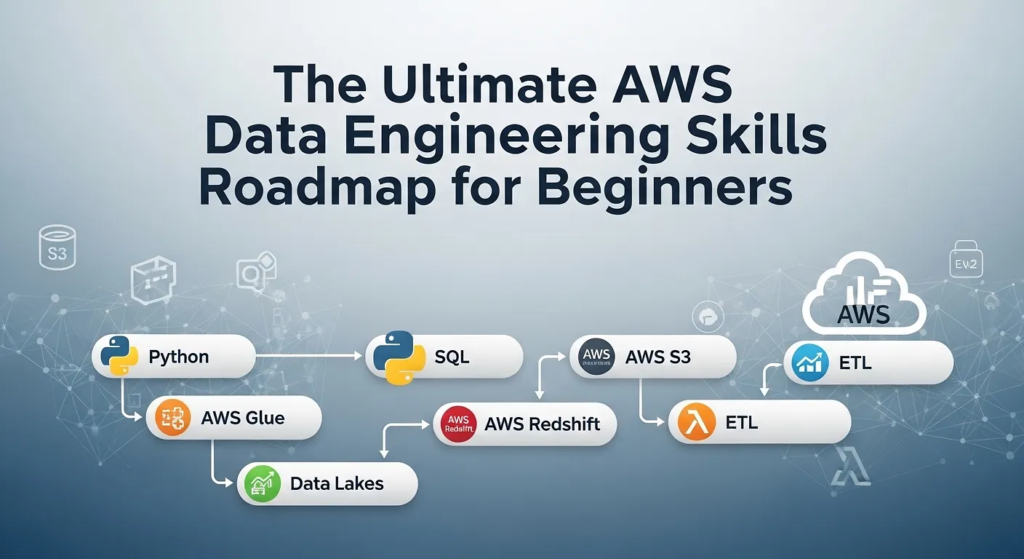
If you want to build a highly lucrative career in tech today, you need to follow the data. In 2026, artificial intelligence, machine learning, and advanced analytics are useless without clean, accessible, and well-structured data. This is exactly why following a structured AWS data engineering skills roadmap is one of the highest-ROI career decisions you can make.
Amazon Web Services (AWS) remains the undisputed market leader in cloud computing. Enterprise companies in the USA and globally rely on AWS to process petabytes of data daily. However, logging into the AWS Management Console for the first time can be terrifying. With over 200 distinct services, where does a beginner even start?
You don’t need to learn everything. You just need to learn the right things in the right order.
In this comprehensive, step-by-step guide, we will break down the exact AWS data engineering skills roadmap you need to go from an absolute beginner to a job-ready data engineer. We will cover the foundational programming languages, the core AWS storage systems, modern ETL processing, and the 2026 trends like Zero-ETL and GenAI integrations that will make your resume stand out.
Learn more: 10 Highest Demand IT Skills for Remote Jobs
Table of Contents
Phase 1: The Non-Negotiable Foundations (Pre-AWS)
Before you touch a single cloud server, you must build a solid foundation. Cloud providers are just renting you someone else’s computer; the logic of data engineering remains the same regardless of where it’s hosted. Do not skip this phase, or you will struggle deeply later.
1. SQL (Structured Query Language)
SQL is the undisputed universal language of data. In 2026, despite the rise of AI coding assistants, knowing how to manipulate data natively using SQL is non-negotiable.
- What to learn: Don’t just stop at SELECT and JOIN. You must master Window Functions (e.g., ROW_NUMBER(), RANK()), Common Table Expressions (CTEs) for readable code, and performance tuning (understanding how indexes and partitions work).
2. Python Programming
Python is the primary programming language for data engineering due to its massive ecosystem of data processing libraries.
- What to learn: Focus on data structures (lists, dictionaries, sets). Master Pandas for small-scale data manipulation.
- Crucial for AWS: You must learn Boto3, the AWS SDK for Python. Boto3 allows you to write Python scripts that automatically create, read, and delete AWS resources (like uploading a file to an S3 bucket via code).
3. Data Architecture and Modeling
How you store data dictates how fast and cheaply you can query it.
- What to learn: Understand the difference between OLTP (Online Transaction Processing – for apps) and OLAP (Online Analytical Processing – for analytics). Learn the Star Schema (Fact and Dimension tables) and familiarize yourself with the Medallion Architecture (Bronze, Silver, Gold layers), which is the standard for modern data lakes in 2026.
Phase 2: Core AWS Storage and Compute
Once your foundations are solid, it is time to step into the AWS ecosystem. The first step in your AWS data engineering skills roadmap is understanding where data lives and how to securely access it.
1. AWS IAM (Identity and Access Management)
Security is job zero at AWS. IAM is how you grant permissions to users and services.
- The Goal: Understand the “Principle of Least Privilege.” If your Python script needs to read a file from AWS, it should only have “Read” access to that specific folder, nothing else. Learn how to create IAM Roles and attach Policies.
2. Amazon S3 (Simple Storage Service)
S3 is the beating heart of AWS data engineering. It is an object storage service that acts as the foundation of your Data Lake.
- The Goal: Learn how to create S3 buckets, manage prefixes (folders), and understand storage tiers (Standard vs. Glacier for archiving).
- 2026 Trend: Learn about open-table formats like Apache Iceberg, Apache Hudi, and Delta Lake. In 2026, we don’t just dump CSVs into S3; we use Iceberg to give S3 data warehouse-like capabilities (like ACID transactions).
3. Amazon EC2 & AWS Lambda
You need compute power to process your data.
- EC2 (Elastic Compute Cloud): These are virtual servers. You should know how to spin up a basic Linux EC2 instance and SSH into it.
- AWS Lambda: This is serverless computing. You write a Python function, and AWS runs it only when triggered (e.g., automatically running a script the second a new CSV is uploaded to S3). Lambda is essential for lightweight, event-driven data pipelines.
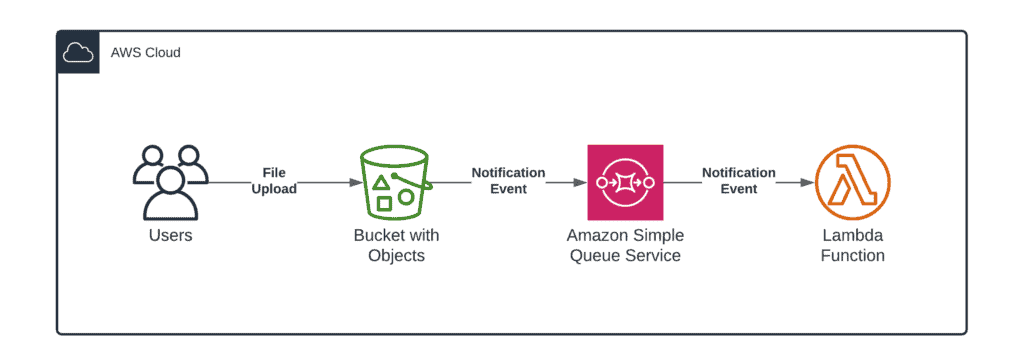
Phase 3: Data Ingestion and ETL/ELT Processing
Data rarely arrives clean or in the right format. ETL (Extract, Transform, Load) is the process of moving data from a source (like a database or an API), cleaning it, and loading it into a destination (like a Data Warehouse).
1. Amazon RDS & Amazon Aurora
Before you extract data, you need to know where it’s coming from. RDS is AWS’s managed relational database service (PostgreSQL, MySQL). Aurora is their proprietary, hyper-fast database engine.
- The Goal: Understand how to connect to these databases and extract data efficiently without crashing the production app.
2. AWS Glue (The Heavy Lifter)
AWS Glue is a serverless data integration service. It is arguably the most critical service to master on your AWS data engineering skills roadmap.
- Glue Data Catalog: Think of this as the index of a book. It automatically scans your S3 buckets and creates a metadata directory of what data exists and its schema (columns and data types).
- Glue ETL Jobs: Glue runs Apache Spark under the hood. You need to learn PySpark (Python API for Spark) to write scripts that can process terabytes of data across distributed clusters seamlessly.
- Glue DataBrew: A visual data preparation tool for cleaning data without writing code (great for quick profiling).
3. Amazon Kinesis & MSK (Real-Time Streaming)
Not all data comes in daily batches. Modern apps require real-time streaming (e.g., tracking user clicks on a website live).
- The Goal: Learn Amazon Kinesis Data Streams and Kinesis Firehose. Firehose is incredibly beginner-friendly; it catches streaming data and automatically dumps it into S3 or Redshift in near real-time. (If a company uses Apache Kafka, AWS offers MSK – Managed Streaming for Apache Kafka).
Phase 4: Data Warehousing and Analytics
Once the data is cleaned and transformed, it needs to be served to Data Analysts, Business Intelligence (BI) tools (like Tableau or Amazon QuickSight), and Machine Learning models.
1. Amazon Redshift
Redshift is AWS’s enterprise-grade Data Warehouse. It uses columnar storage, making it lightning-fast for analytical queries (e.g., “What was the average sales revenue across all US stores in the last 5 years?”).
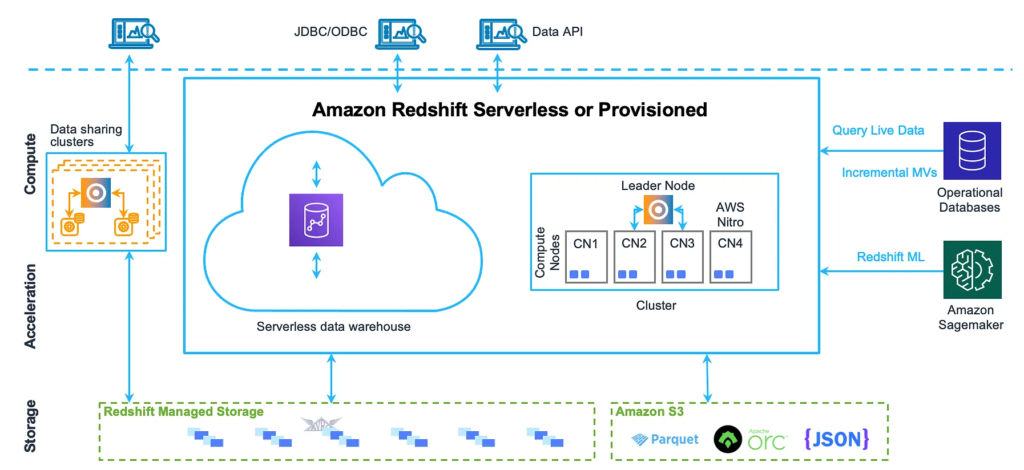
- 2026 Trend Focus: Focus entirely on Redshift Serverless. Companies are moving away from provisioning clusters manually. Also, heavily study Zero-ETL integrations. AWS now allows data to flow directly from Amazon Aurora into Redshift automatically, without you needing to build a pipeline in AWS Glue! Knowing when to use Zero-ETL versus traditional ETL is a senior-level insight.
2. Amazon Athena
Athena is an interactive query service that allows you to analyze data directly in Amazon S3 using standard SQL.
- Why it’s powerful: There is no server to set up. You just point Athena at your S3 bucket (using the Glue Data Catalog) and write a SQL query. You pay purely for the data scanned. It is the best tool for ad-hoc data exploration.
Phase 5: Orchestration and Workflow Management
If you have a Python script, a Glue job, and a Redshift query, how do you make sure they run in the correct order automatically every night at 2:00 AM? This is orchestration.
1. AWS Step Functions
A visual, serverless orchestration service that lets you combine AWS Lambda functions and other AWS services into business-critical applications. It’s perfect for simple, AWS-native workflows.
2. Amazon MWAA (Managed Workflows for Apache Airflow)
In the global tech industry, Apache Airflow is the industry standard for orchestrating complex data pipelines. Instead of managing the Airflow infrastructure yourself, AWS offers MWAA.
- The Goal: Learn how to write Directed Acyclic Graphs (DAGs) in Python. A DAG is simply a script that tells Airflow: “Run Task A. If Task A succeeds, run Task B. If Task A fails, send an alert to Slack.”
Phase 6: The 2026 Differentiators (Governance & AI)
If you want to surpass the competition and land a high paying remote IT job, you must understand the cutting-edge tools defining 2026.
1. AWS Lake Formation (Security & Governance)
As your Data Lake grows, managing who can access what becomes a nightmare. Lake Formation sits on top of S3 and Glue. It allows you to set fine-grained permissions (e.g., hiding the “Social Security Number” column from junior analysts while letting them query the rest of the table).
2. AWS Clean Rooms
With stricter global privacy laws in 2026, AWS Clean Rooms allow multiple companies to combine and analyze their data without actually sharing or revealing the underlying raw data to each other. Understanding this makes you highly valuable to ad-tech and finance companies.
3. Amazon Bedrock for Data Engineering
Generative AI has fundamentally changed data engineering. Using Amazon Bedrock (AWS’s managed service for foundational models like Claude 3 or Titan), modern data engineers are automating the tedious parts of their jobs.
- The Goal: Learn how to integrate LLMs into your pipelines to automatically generate data quality rules, detect anomalies in incoming datasets, or translate legacy SQL code into PySpark.
How to Become an AWS Data Engineer with No Experience
Reading a roadmap is easy; walking it is hard. Here is your actionable blueprint:
- Months 1-2: Master the Basics. Spend 8 weeks exclusively on SQL, Python, and understanding data modeling concepts. Do not look at AWS yet.
- Month 3: Get AWS Certified Cloud Practitioner. This foundational certification will teach you cloud terminology, pricing models, and basic infrastructure concepts.
- Months 4-5: Build Core Pipelines. Open an AWS Free Tier account. Build a project where a Python script pulls data from a free public API (like weather data), saves it to S3, cleans it using AWS Glue, and queries it with Athena.
- Month 6: Master Orchestration & Portfolio. Learn Apache Airflow. Automate your previous project to run daily. Document the entire architecture with diagrams on a GitHub repository.
- Month 7: Target the Specialized Certification. Study for and pass the AWS Certified Data Engineer – Associate (DEA-C01) exam. This specific certification proves to employers that you understand modern, 2026-relevant data architectures.
AWS Data Engineering Path Summary
To become an AWS Data Engineer, follow this sequential skill roadmap:
- Learn core languages: Master SQL, Python, and Pandas.
- Understand AWS storage: Learn Amazon S3, IAM security, and open-table formats like Apache Iceberg.
- Master Serverless Compute: Use AWS Lambda for event-driven processing.
- Build ETL Pipelines: Learn AWS Glue and PySpark for big data transformation.
- Set up Data Warehousing: Master Amazon Redshift and Redshift Serverless capabilities.
- Query S3 Directly: Use Amazon Athena for serverless SQL data exploration.
- Orchestrate Workflows: Automate pipelines using Amazon MWAA (Apache Airflow) or Step Functions.
Frequently Asked Questions (FAQs)
Q: Do I need strong math skills to be a data engineer?
A: No. Unlike Data Scientists or Machine Learning Engineers who require deep knowledge of statistics and calculus, Data Engineers are essentially specialized software engineers. Your focus is on infrastructure, system architecture, and moving data reliably. Logic and problem-solving are much more important than complex math.
Q: How much does it cost to learn AWS data engineering?
A: Most of your learning can be done for free or pennies. The AWS Free Tier provides limited free usage of S3, Lambda, and Glue. However, be extremely careful to set up AWS Budgets and billing alarms on day one so you don’t accidentally run a massive cluster and incur unexpected charges.
Q: Is the AWS Solutions Architect certification good for Data Engineers?
A: Yes, it is a fantastic foundational certification. However, as of recent updates, the AWS Certified Data Engineer – Associate is the most direct, targeted credential you can get to bypass HR filters for data engineering roles.
Q: Should I learn AWS, Azure, or GCP first?
A: AWS holds the largest market share globally and in the USA, meaning there are more job openings. However, the concepts (Data Lakes, ETL, Warehousing) are identical across all three. Once you learn AWS, transitioning to Azure (Data Factory) or GCP (BigQuery) takes a fraction of the time.
Conclusion
Embarking on the AWS data engineering skills roadmap is an exciting journey into one of the most resilient and highly compensated fields in tech. By methodically mastering the foundations of Python and SQL, progressing through S3 storage, tackling Glue and PySpark, and wrapping your pipelines in robust Airflow orchestration, you transform yourself from a beginner into a highly capable cloud professional.
The data revolution of 2026 is moving faster than ever. Take it one service at a time, rely heavily on hands-on building rather than just watching tutorials, and start assembling your portfolio today.



